# 字符串处理工具 - 网站操作说明
## 工具概述
字符串处理工具是一个功能强大的文本处理平台,提供多种字符串操作功能,适用于数据清洗、内容提取、格式转换等多种场景。工具采用分类标签页设计,操作简单直观。
## 界面布局
- **上半部分**:功能操作区域,包含5个功能标签页
- **下半部分**:数据处理区域,分为三个区域:
- 左侧:数据源输入区
- 右上:操作日志显示区
- 右下:结果数据输出区
---
## 功能分类详解
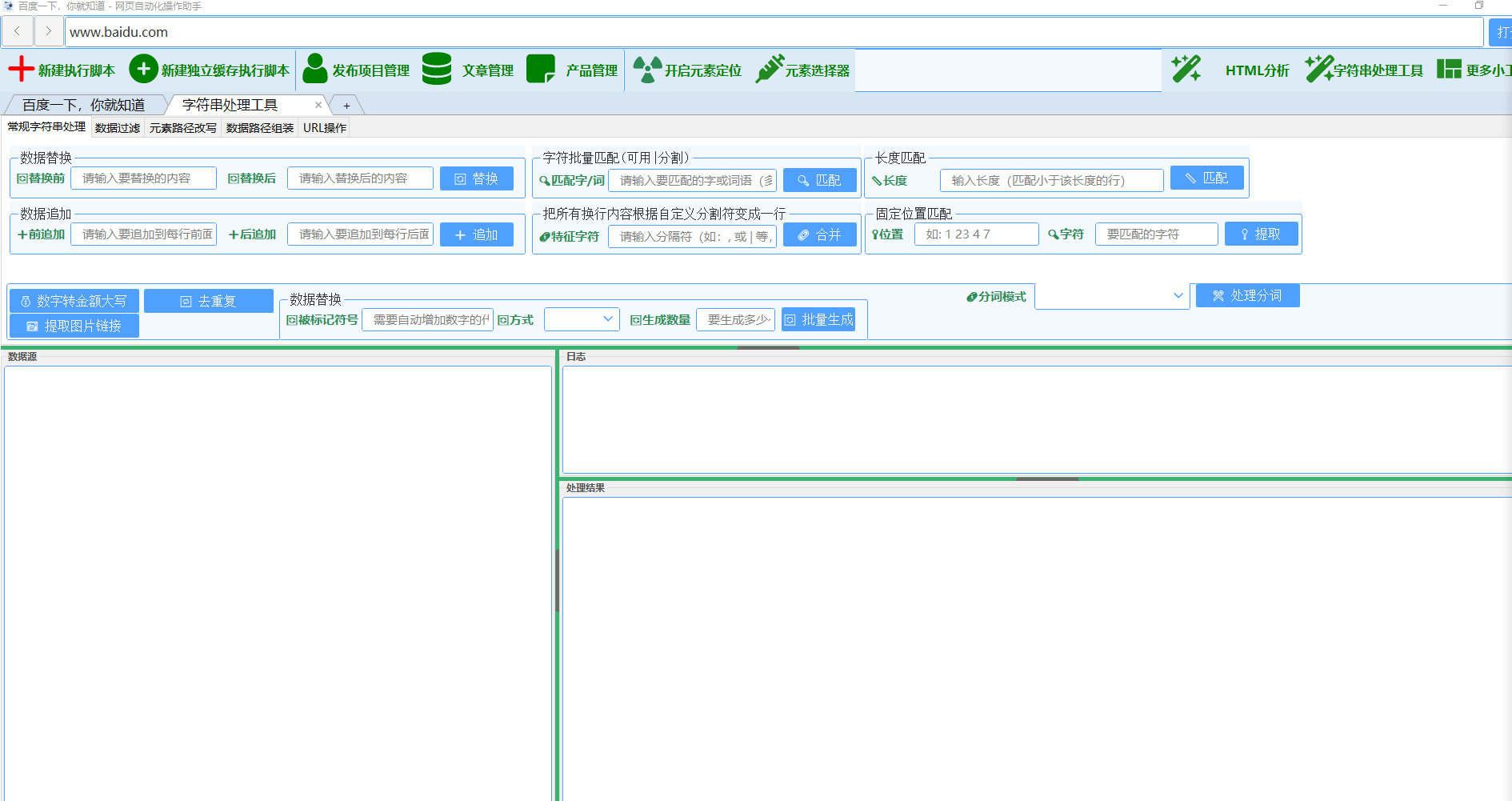
### 1. 常规字符串处理
#### 1.1 替换功能
**功能描述**:对数据源中的指定内容进行批量替换
- **输入参数**:
- 替换前数据:要被替换的内容
- 替换后数据:替换成的新内容
- **处理方式**:逐行处理,支持多次替换
- **使用场景**:
- 批量修改文本内容
- 统一格式调整
- 敏感词替换
#### 1.2 追加功能
**功能描述**:在每行数据的前面或后面添加指定内容
- **输入参数**:
- 前追加数据:在行首添加的内容
- 后追加数据:在行尾添加的内容
- **处理方式**:逐行处理,可同时前后追加
- **使用场景**:
- 添加统一前缀或后缀
- 格式化数据输出
- 生成特定格式的代码或配置
#### 1.3 匹配内容
**功能描述**:根据关键词匹配数据,实现数据分离
- **输入参数**:匹配词(支持用|分隔多个关键词)
- **处理逻辑**:
- 匹配到的行显示在结果数据中
- 未匹配的行更新回数据源(实现数据减少)
- **使用场景**:
- 数据筛选和分类
- 关键词提取
- 内容过滤
#### 1.4 合并行
**功能描述**:将多行数据合并为一行,用指定分隔符连接
- **输入参数**:特征字符(分隔符,默认为逗号)
- **处理方式**:过滤空行,用分隔符连接所有有效行
- **使用场景**:
- 生成CSV格式数据
- 创建参数列表
- 数据压缩展示
#### 1.5 固定位置匹配
**功能描述**:根据字符在行中的固定位置进行匹配
- **输入参数**:
- 位置信息:如"1 23 4 7"(空格分隔,位置从1开始)
- 匹配字符:要匹配的字符
- **处理逻辑**:检查指定位置是否包含匹配字符
- **使用场景**:
- 结构化数据验证
- 格式检查
- 特定位置内容提取
#### 1.6 长度匹配
**功能描述**:筛选出长度小于指定值的所有行
- **输入参数**:长度限制(正整数)
- **处理方式**:按字符长度过滤
- **使用场景**:
- 数据质量检查
- 短内容筛选
- 长度规范验证
#### 1.7 数字转金额大写
**功能描述**:将文本中的数字转换为中文金额大写
- **处理方式**:自动识别数字并转换
- **使用场景**:
- 财务单据处理
- 合同金额转换
- 发票内容生成
#### 1.8 去重复
**功能描述**:删除重复的行,保留唯一内容
- **处理方式**:基于行内容去重,保持原有顺序
- **使用场景**:
- 数据清洗
- 列表去重
- 内容整理
#### 1.9 分词处理
**功能描述**:对中文文本进行智能分词
- **分词模式**:
- 精准模式:最精确的分词结果
- 全模式:扫描所有可能的词语
- 搜索引擎模式:适合搜索引擎的分词
- **使用场景**:
- 文本分析
- 关键词提取
- 搜索优化
#### 1.10 URL批量生成
**功能描述**:根据模板和规则批量生成URL
- **输入参数**:
- 标记符:模板中的占位符
- 方式:递增或递减
- 起始值:生成的数量
- **使用场景**:
- 批量URL生成
- 测试数据创建
- 链接模板处理
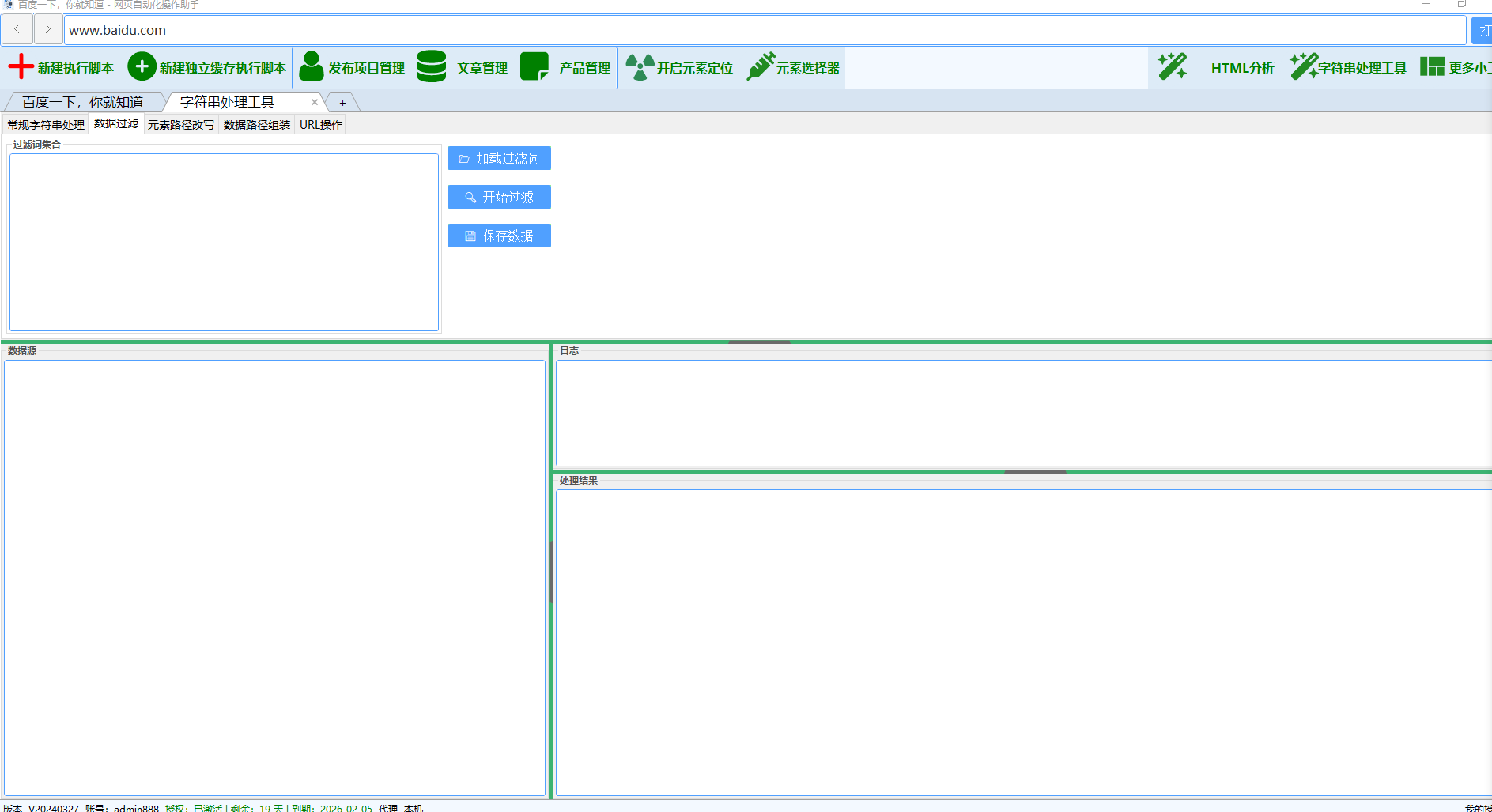
### 2. 违禁词过滤
#### 2.1 加载过滤词
**功能描述**:从系统文件加载违禁词库
- **文件路径**:根目录/plus/违禁词.txt
- **处理方式**:自动去重和排序
- **使用场景**:
- 内容审核准备
- 违禁词库管理
#### 2.2 开始过滤违禁词
**功能描述**:根据违禁词库过滤数据源内容
- **处理方式**:删除包含违禁词的内容
- **使用场景**:
- 内容合规检查
- 敏感信息过滤
- 文本净化
#### 2.3 保存违禁词
**功能描述**:将当前违禁词集合保存到文件
- **保存格式**:UTF-8编码,每行一个词
- **使用场景**:
- 违禁词库维护
- 规则备份
### 3. 元素路径改写
#### 3.1 CSS选择器优化
**功能描述**:智能改写动态CSS选择器
- **处理方式**:优化选择器的稳定性和准确性
- **使用场景**:
- 网页自动化脚本优化
- 爬虫选择器改进
- 前端测试脚本维护
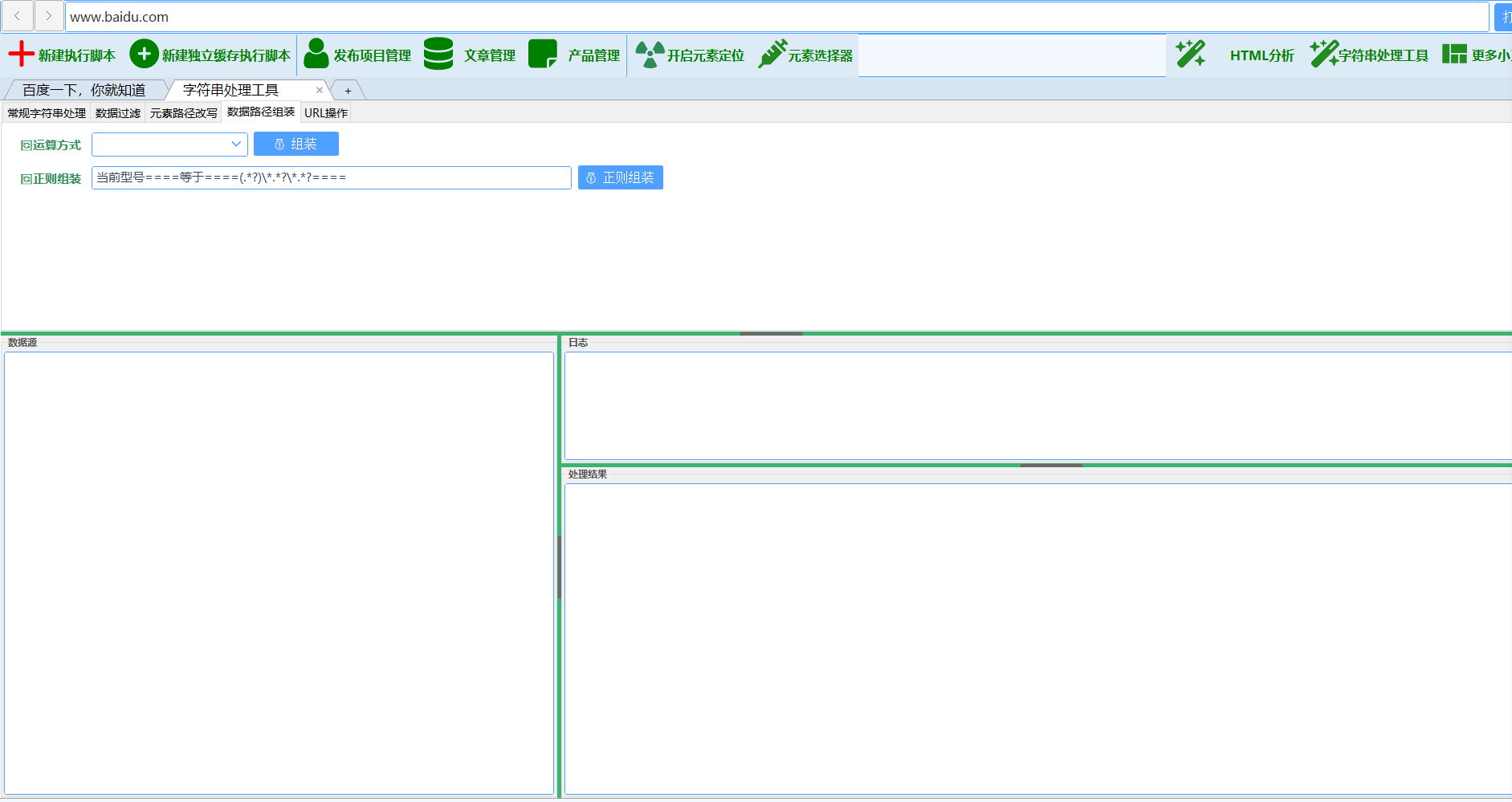
### 4. 数据组装
#### 4.1 运算组装
**功能描述**:根据运算方式生成特定格式的数据
- **运算方式**:
- 包含:生成包含判断格式
- 等于:生成等于判断格式
- 批量替换:生成替换操作格式
- **使用场景**:
- 规则引擎数据生成
- 条件语句创建
- 批处理脚本生成
#### 4.2 正则组装
**功能描述**:使用正则表达式提取并组装数据
- **输入参数**:正则组装表达式
- **处理方式**:提取第一个捕获组并与原数据组装
- **使用场景**:
- 数据提取和重组
- 格式化输出
- 结构化数据生成
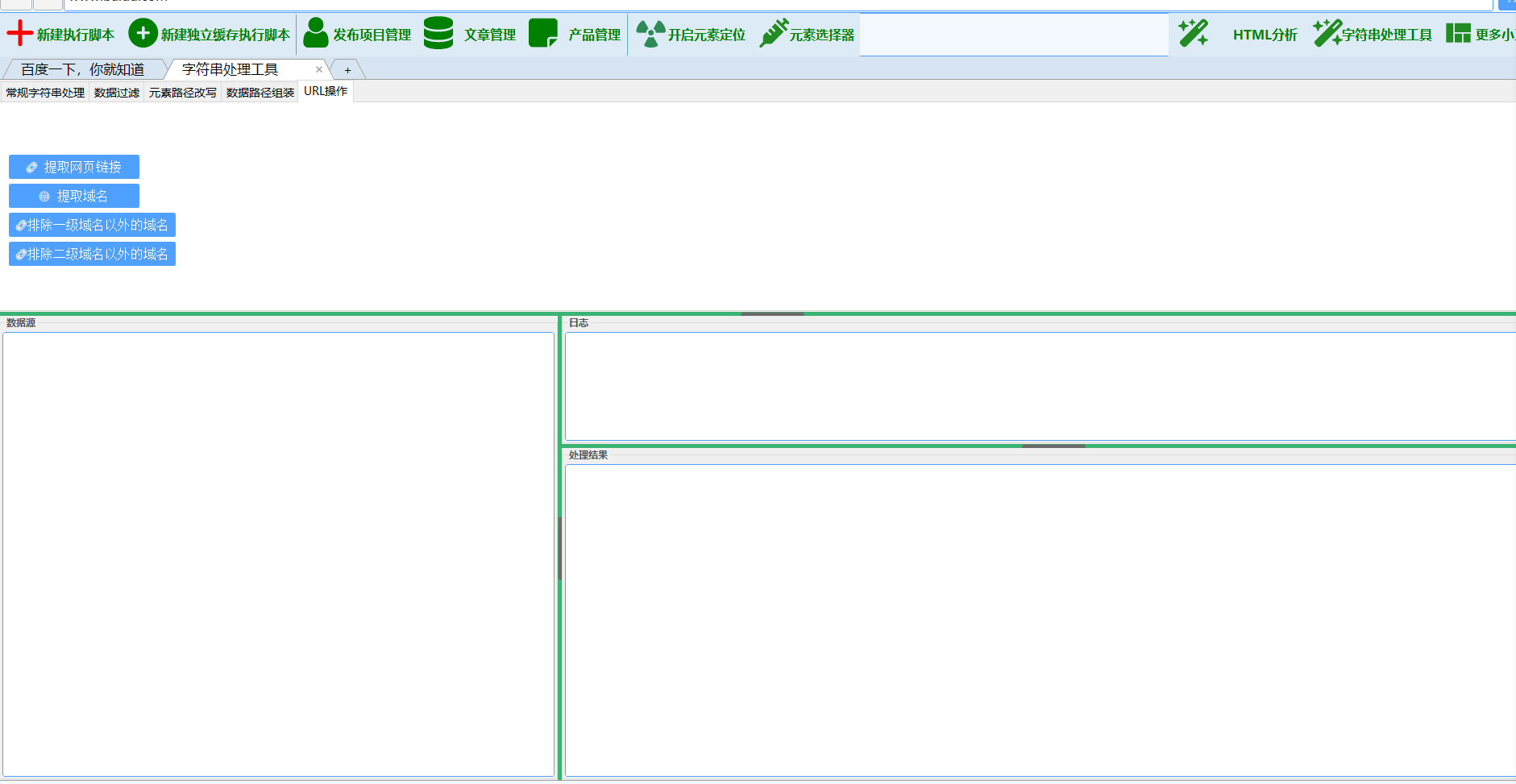
### 5. 链接处理
#### 5.1 提取图片链接
**功能描述**:从HTML或文本中提取图片链接
- **支持格式**:jpg、jpeg、png、gif、bmp、webp、svg、ico
- **提取方式**:支持img标签和直接URL
- **使用场景**:
- 网页图片收集
- 资源链接整理
- 媒体文件管理
#### 5.2 提取网页链接
**功能描述**:从HTML或文本中提取网页链接
- **提取方式**:支持a标签href和直接URL
- **使用场景**:
- 链接收集
- 网站分析
- SEO优化
#### 5.3 提取域名
**功能描述**:从URL中提取域名信息
- **处理方式**:智能识别并去重
- **使用场景**:
- 域名统计
- 网站分析
- 安全检查
#### 5.4 域名级别筛选
**功能描述**:按域名级别进行筛选
- **一级域名筛选**:只保留如example.com格式的域名
- **二级域名筛选**:保留一级和二级域名(如www.example.com)
- **使用场景**:
- 域名分类管理
- 网站层级分析
- 安全策略制定
---
## 操作流程
### 基本操作步骤:
1. **输入数据**:在"数据源"区域输入要处理的文本
2. **选择功能**:点击相应标签页,选择需要的处理功能
3. **设置参数**:根据功能要求填写相关参数
4. **执行处理**:点击对应的功能按钮
5. **查看结果**:在"结果数据"区域查看处理结果
6. **查看日志**:在"操作日志"区域查看处理详情
### 高级操作技巧:
- **数据流转**:某些功能会自动更新数据源,实现数据的逐步筛选
- **批量处理**:支持大量数据的批量处理
- **结果复用**:可将结果数据复制回数据源进行二次处理
- **参数保存**:工具会记住上次使用的参数设置
---
## 应用场景
### 数据清洗场景:
- 去除重复数据
- 过滤无效内容
- 统一数据格式
- 提取有效信息
### 内容处理场景:
- 敏感词过滤
- 格式转换
- 批量替换
- 内容重组
### 开发辅助场景:
- 生成测试数据
- 优化选择器
- 批量生成代码
- 数据格式转换
### SEO优化场景:
- 提取网站链接
- 分析域名结构
- 收集图片资源
- 关键词分析
---
## 注意事项
1. **数据备份**:处理重要数据前建议先备份
2. **格式检查**:确保输入数据格式正确
3. **参数验证**:仔细检查输入参数的有效性
4. **结果验证**:处理完成后验证结果的正确性
5. **性能考虑**:处理大量数据时可能需要较长时间
---
## 技术支持
如遇到问题或需要技术支持,请查看操作日志中的详细错误信息,或联系技术支持团队获取帮助。